

Landslide Denied
Landslide Denied: Exit Polls vs. Vote Count 2006
and the Corruption of the Official Vote Count
Jonathan Simon, JD, and Bruce O’Dell1
Election Defense Alliance
Click to Download This Article
Introduction: Pre-Election Concern, Election Day Relief, Alarming Reality
There was an unprecedented level of concern approaching the 2006 Election (“E2006”) about the vulnerability of the vote counting process to manipulation. With questions about the integrity of the 2000, 2002 and 2004 elections remaining unresolved, with e-voting having proliferated nationwide, and with incidents occurring with regularity through 2005 and 2006, the alarm spread from computer experts to the media and the public at large. It would be fair to say that America approached E2006 with held breath.
For many observers, the results on Election Day permitted a great sigh of relief—not because control of Congress shifted from Republicans to Democrats, but because it appeared that the public will had been translated more or less accurately into electoral results, not thwarted as some had feared. There was a relieved rush to conclude that the vote counting process had been fair and the concerns of election integrity proponents overblown.
Unfortunately the evidence forces us to a very different and disturbing conclusion: there was gross vote count manipulation and it had a great impact on the results of E2006, significantly decreasing the magnitude of what would have been, accurately tabulated, a landslide of epic proportions. Because much of this manipulation appears to have been computer-based, and therefore invisible to the legions of at-the-poll observers, the public was informed of the usual “isolated incidents and glitches” but remains unaware of the far greater story: The electoral machinery and vote counting systems of the United States did not honestly and accurately translate the public will and certainly can not be counted on to do so in the future.
_________________________________________________________________________________________________________________
1 Jonathan Simon, JD (http://www.electiondefensealliance.org/jonathan_simon) is Co-founder of Election Defense Alliance. Bruce O'Dell (http://www.electiondefensealliance.org/bruce_odell) is EDA Data Analysis Coordinator.
________________________________________________________________________________________________________________
The Evidentiary Basis
Our analysis of the distortions introduced into the E2006 vote count relies heavily on the official exit polls once again undertaken by Edison Media Research and Mitofsky International (“Edison/Mitofsky”) on behalf of a consortium of major media outlets known as the National Election Pool (NEP). In presenting exit poll-based evidence of vote count corruption, we are all too aware of the campaign that has been waged to discredit the reliability of exit polls as a measure of voter intent.
Our analysis is not, however, based on a broad assumption of exit poll reliability. Rather we maintain that the national exit poll for E2006 contains within it specific questions that serve as intrinsic and objective yardsticks by which the representative validity of the poll’s sample can be established, from which our conclusions flow directly.
For the purposes of this analysis our primary attention is directed to the exit poll in which respondents were asked for whom they cast their vote for the House of Representatives.
When we compare the results of this national exit poll with the total vote count for all House races we find that once again, as in the 2004 Election (“E2004”), there is a very significant exit poll-vote count discrepancy. The exit poll indicates a Democratic victory margin nearly 4%, or 3 million votes, greater than the margin recorded by the vote counting machinery. This is far outside the margin of error of the poll and has less than a one in 10,000 likelihood of occurring as a matter of chance.
___________________________________________________________________________________________
2 Edison/Mitofsky exit polls for the Senate races also present alarming discrepancies and will be treated in a separate paper. The special significance of the House vote is that, unlike the Senate vote, it offers a nationwide aggregate view.
3 The sample size was roughly equal to that used to measure the national popular vote in presidential elections. At-precinct interviews were supplemented by phone interviews where needed to sample early and absentee voters.
4 We note with interest and raised brows that the NEP is now giving the MOE for their national sample as +/-3% (http://www.exit-poll.net/faq.html#a15). This is rather curious, as their published Methods Statement in 2004 assigns to a sample of the same size and mode of sampling the expected MOE of +/-1% (see Appendix 2 for both NEP Statements). Perhaps the NEP intends its new methodology statement to apply to its anticipated effort in 2008 and is planning to reduce the national sample size by 75% for that election; we hope not. It of course makes no sense, as applied to E2004 or E2006, that state polls in the 2000-respondent range should yield a MOE of +/-4%, as stated, while a national poll of more than five times that sample size should come in at +/-3%. It would certainly be useful in quelling any controversy that has arisen or might arise from exit poll-vote count disparities far outside the poll’s MOE, but it is, to our knowledge, not the way that statistics and mathematics work.
_____________________________________________________________________________________________
The Exit Polls and The Vote Count
In E2004 the only nontrivial argument against the validity of the exit polls—other than the mere assumption that the vote counts must be correct—turned out to be the hypothesis, never supported by evidence, that Republicans had been more reluctant to respond and that therefore Democrats were "oversampled." And now, in E2006, the claim has once again been made that the Exit Polls were "off" because Democrats were oversampled.
Any informed discussion of exit polling must distinguish among three separate categories of data:
1) “Raw” data, which comprises the actual responses to the questionnaires simply tallied up; this data is never publicly released and, in any case, makes no claim to accurately represent the electorate and can not be usefully compared with vote counts.
2) “Weighted” data, in which the raw data has been weighted or stratified on the basis of numerous demographic and voting pattern variables to reflect with great accuracy the composition and characteristics of the electorate.
3) “Forced” or “Adjusted” data, in which the pollster overrides previous weighting in order to make the "Who did you vote for?" result in a given race match the vote count for that race, however it distorts the demographics of the sample (that's why they call it "forcing").
Because the NEP envisions the post-election purpose of its exit polls as being limited to facilitating academic dissection of the election’s dynamics and demographics (e.g., “How did the 18-25 age group vote?” or “How did voters especially concerned with the economy vote?”), the NEP methodology calls for correcting or "adjusting" its exit polls to congruence with the actual vote percentages after the polls close and actual returns become available. Exit polls are "corrected" on the ironclad assumption that the vote counts are valid. This becomes the supreme truth, relative to which all else is measured, and therefore it is assumed that polls that match these vote counts will present the most accurate information about the demographics and voting patterns of the electorate. A distorted electorate in the adjusted poll is therefore a powerful indicator of an invalid vote count.
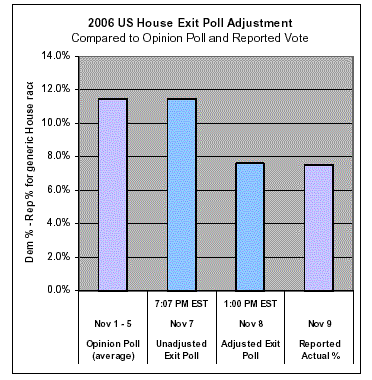
We examined both “weighted” and “adjusted” exit polls of nationwide vote for the House of Representatives published by the NEP. On Election Night, November 7, 2006 at 7:07 p.m., CNN.com posted a national exit poll that was demographically weighted but not yet adjusted to congruence with the vote counts.
The 2006 national vote for the House, as captured by the Weighted National Poll, was 55.0% Democratic and 43.5% Republican—an 11.5% Democratic margin. By 1:00 p.m. on November 8, the Adjusted National Poll reported the overall vote for the House as 52.6% Democratic and 45.0% Republican, just a 7.6% margin.
___________________________________________________________________________________________
5 See for example David Bauder, AP, in a November 8 article at http://www.washingtonpost.com/wpdyn/content/article/2006/11/08/AR2006110800403.html. Oddly enough, “oversampling” of Democrats has become a chronic ailment of exit polls since the proliferation of e-voting, no matter how diligently the nonpartisan collection of experts at the peak of their profession strives to prevent it. Of course the weighting process itself is undertaken to bring the sample into close conformity with the known and estimated characteristics of the electorate, including partisanship; so the fact that more of a given party’s adherents were actually sampled, while it would be reflected in the unpublished raw data, would not in fact bias or affect the validity of the published weighted poll. That is the whole point of weighting, in light of which the hand-wringing about Democratic oversampling strikes us as misunderstanding at best, and quite possibly intended misdirection.
6 The 7:07 p.m. poll reported a 10,207 sample size and, in accordance with NEP methodology, the raw data had been weighted to closely match the demographics of the electorate.
7 Analysts noticing the substantial increase in “respondents” between the Weighted (10,207) and Adjusted (13,251) National Polls may understandably but erroneously conclude that the shift between the two polls is the result of a late influx of Republican-leaning respondents. This is not the way it works. Since these are both weighted polls, each is in effect “tuned” to a profile of the electorate assumed to be valid—the Weighted National Poll to a set of established demographic variables and the Adjusted National Poll to the vote count once it is tabulated. The published number of respondents is irrelevant to this process and has significance only as a guide to the poll’s margin of error. 10,000+ respondents is a huge sample (cf. the 500 – 1500 range of most tracking polls), and obviously an ample basis on which to perform the demographic weighting manifest in the Weighted National Poll.
_____________________________________________________________________________________________
Did The 2006 Exit Poll Oversample Democrats? Cross-tabs Answer This Question
The national exit poll administered by Edison/Mitofsky for the NEP is not, as some may imagine, a simple “Who did you vote for?” questionnaire. It poses some 40 to 50 additional questions pertaining to demographic, political preference, and state-of-mind variables. Voters are asked, for example, about such characteristics as race, gender, income, age, and also about such things as church attendance, party identification, ideology, approval of various public figures, importance of various issues to their vote, and when they made up their minds about whom to vote for.
When the poll is posted, these characteristics are presented in a format, known as “cross-tabs,” in which the voting choice of respondents in each subgroup is shown. For example, respondents were asked whether they thought the United States “is going in the right direction.” In the Weighted National Poll the cross-tab for this characteristic (see below) shows us that 40% said Yes and 56% said No; and further that, of the 40% subgroup who said Yes, 21% voted Democrat and 78% voted Republican for House of Representatives, while, of the 56% who said No, 80% voted Democrat and 18% voted Republican. We also see that this question is quite highly correlated with voting preference, with fully four-fifths of the “pessimists” voting Democratic.

Cross-tabs vary greatly in the degree to which the characteristic is correlated with voting preference. The more strongly correlated, the more important the cross-tab becomes in assessing the poll’s validity as an indicator of the vote.
Prior to public posting the exit poll data is weighted according to a variety of demographics, in such a way that the resulting cross-tabs closely mirror the expected, independently measurable characteristics of the electorate as a whole. The cross-tabs, in turn, tell us about the sample, giving us detailed information about its composition and representativeness. This information is of critical importance to our analysis because among the many questions asked of respondents there are several that enable us to tell whether the sample is valid or politically biased in one direction or another. These are the “intrinsic yardsticks” to which we have made reference.
Among the most salient yardstick questions were the following:
• Job Approval of President Bush
• Job Approval of Congress
• Vote for President in 2004
With respect to each of these yardsticks the composition of the sample can be compared to measures taken of the voting population as a whole, giving us a very good indication of the validity of the sample. Examining these cross-tabs for the Weighted National Poll—the 7:07 p.m. poll that was written off by the media as a “typical oversampling of Democrats”—this is what we found:
• Approval of President Bush: 42%
• Approval of Congress: 36%
• Vote for President in 2004: Bush 47%, Kerry 45%
When we compare these numbers with what we know about the electorate as a whole going into E2006, we can see at once that the poll that told us that the Democratic margin was 3 million votes greater than the computers toted up was not by any stretch of the imagination an oversampling of Democrats. Let’s take each yardstick in turn.
Presidential Approval Rating
We can compare the 42% approval of President Bush in the Weighted National Poll with any or all of the host of tracking polls measuring this critical political variable in the weeks and days leading up to the election. It is important when comparing approval ratings to make sure that we compare apples with apples, since the question can be posed in different ways leading to predictably different results. The principal formats of the approval measure are either simply “Do you approve or disapprove. . .?” or “Do you strongly approve, somewhat approve, somewhat disapprove, or strongly disapprove. . .?” We can call these the two-point and four-point formats respectively. By repeatedly posing the question in both formats on the same days, it has been determined that the four-point format consistently yields an approval rating 3-4% higher than the two-point format.
Bearing this in mind and comparing the Weighted National Poll respondents’ approval of President Bush with that registered by the electorate going into the election, we find very close parity. PollingReport.com catalogues 33 national polls of Presidential approval taken between October 1 and Election Day using the two-point format, with an average (mean) approval rating of 37.6%.

Congressional Approval Rating
As with the Presidential approval yardstick, comparison between the 36% of the Weighted National Poll sample that approved of how Congress was handling its job and the value established for the electorate in numerous tracking polls corroborates the Weighted National Poll’s validity. The mean of the 17 national polls catalogued by the PollingReport.com measuring approval of Congress between October 1 and Election Day (all employing the two-point format) was 27.5% approval.

_______________________________________________________________________________________________
8 http://www.rasmussenreports.com/public_content/politics/polling_methodology_job_approval_ratings. As Rasmussen notes, the 3-4% upwards adjustment in the four-point format impounds the virtual elimination of the “Not Sure” response obtained with greater frequency in the two-point format.
9 http://www.pollingreport.com/BushJob.htm. Typical of the national polls included are Gallup, AP-Ipsos, Newsweek, Fox/Opinion Dynamics, CBS/New York Times, NBC/Wall Street Journal, and ABC/Washington Post. The median approval rating is 37.4%, indistinguishable from the mean, and there is no discernible trend up or down over the Oct.1 – Nov. 7 period.
10 http://www.rasmussenreports.com/public_content/politics/political_updates/president_bush_job_approval. The rating combines “strong” and “somewhat” approve and is the average of Rasmussen’s daily tracking polls conducted throughout the month.
11 http://www.pollingreport.com/CongJob.htm.
_______________________________________________________________________________________________
Vote for President in 2004
Edison/Mitofksy asked all respondents how they had voted in the 2004 Presidential election. The Weighted National Poll sample included 45% who said they had voted for Kerry and 47% who said they had voted for Bush (8% indicating they had not voted or voted for another candidate). This Bush margin of +2% closely approximates the +2.8% margin that Bush enjoyed in the official popular vote count for E2004.

While poll respondents have often shown some tendency to indicate they voted for the sitting president when questioned at the time of the next presidential election (i.e., four years out), Bush’s historically low approval rating, coupled with his high relevance to this off-year election, and the shorter time span since the vote in question, make such a generic “winner’s shift” singularly unlikely in E2006.
And while we present the reported 2.8% Bush margin in 2004 at face value, it will not escape notice that the distortions in vote tabulation that we establish in the current paper were also alleged in 2004, were evidenced by the 2004 exit polls, and were demonstrably achievable given the electronic voting systems deployed at that time. We note that, if upon retrospective evaluation the unadjusted 2004 exit polls prove as accurate as the 2006 exit polls appear to be, and their 2.5% margin for Kerry in 2004 is taken as the appropriate baseline, a correctly weighted sample in 2006 would have included even more Kerry voters and even fewer Bush voters than Edison/Mitofsky’s Weighted National Poll, with a substantial consequent up-tick in the Democratic margin beyond the 3 million votes thus far unaccounted for.
The three yardsticks presented above clearly refute the glib canard that the National Exit Poll disparity was due to an oversampling of Democrats. Two other cross-tabs are worthy of note in this regard: Vote By Race and Vote By Party ID.
Vote By Race
The Weighted National Poll sample, as can be seen below, is 80% White, 10% African-American, and 8% Latino in composition, with Whites splitting their vote evenly between the parties while Latinos and particularly Blacks voted overwhelmingly Democratic.

We can compare these demographics with an established measure of the electorate published by the University of Michigan Center for Political Studies. The ANES Guide To Public Opinion and Electoral Behavior, is a longitudinal study of many aspects of the American electorate, including racial composition.

As can be seen by comparing the charts above, in none of the past six elections was the White participation as high or the Black participation as low as represented in the Weighted National Poll.
______________________________________________________________________________________________
12 The American National Election Studies; see www.electionstudies.org. Produced and distributed by the University of Michigan, Center for Political Studies; based on work supported by the National Science Foundation and a number of other sponsors.
13 The full chart, dating to 1948, may be referenced at http://www.electionstudies.org/nesguide/toptable/tab1a_3.htm.
14 Asian and Native American voters, also strong Democratic constituencies, likewise seem to be significantly under-represented in the Weighted National Poll. The ANES results for 2006 are due to be published later this year. In E2004 the Weighted National Poll was 77% White and 11% Black, as opposed to the ANES proportions of 70% and 16% respectively. It was this disproportionately White sample—supposedly short on “reluctant” Bush responders, but in reality overstocked with White voters who favored Bush by a margin of 11% and understocked with Black voters who favored Kerry by a margin of 80%!—that gave Kerry a 2.5% victory in the nationwide popular vote.
____________________________________________________________________________________________
Vote By Party ID
Though Vote By Party ID generally fluctuates relatively modestly from one election to the next, it is, not surprisingly, nonetheless sensitive to the dynamics of atypical turnout battles. While we will address the E2006 turnout dynamics more fully in a later section, for the present we will simply note that a Democratic turnout romp was generally acknowledged in 2006, Republican voters having a number of late-breaking reasons for staying home.
In the Weighted National Poll, Democratic voters comprised 39% of the sample to 35% for the Republicans, as shown below.

Only 20 states register their voters by party so there is no direct comparison to be made to actual registration figures. But the ANES Guide once again proves useful. The chart below records party identification amongst the electorate as a whole on a seven-point scale, but the comparison is convincing.

In each of the past six biennial national elections through 2004, self-identified Democrats have outnumbered Republicans. The margins for 1994, 1996, 1998, 2000, 2002, and 2004 have been +4%, +10%, +11%, +10%, +4%, and +5% respectively. If Independent leaners are included, the Democratic margin increases every year, to +5%, +12%, +14%, +12%, +6%, and +10% respectively. These are very consistent numbers confirming a consistent plurality of self-identified Democratic voters from election to election.
While it would probably insult the intelligence of the media analysts who proclaimed that the E2006 Weighted National Poll was “off” because it had oversampled Democrats to even suggest the possibility that one or more of them took the 39% - 35% Democratic ID margin in the poll to be indicative of Democratic oversampling—such misinterpretation quickly spreading among, and taking on the full authority of, the Election Night punditry—it is very difficult to comprehend by what other measure the Election Night analysts, and all who followed their lead, might have reached that manifestly erroneous, though obviously comforting, conclusion.
In short, there is no measure anywhere in the Weighted National Poll—in which the Democratic margin nationwide was some 3 million votes greater than tabulated by the machines—that indicates an oversampling of Democrats. Any departures from norms, trends, and expectations indicate just the opposite: a poll that likely undersampled Democratic voters and so, at 11.5%, understated the Democratic victory margin.
________________________________________________________________________________________________
15 The full chart, dating to 1952, may be referenced at http://www.electionstudies.org/nesguide/toptable/tab2a_1.htm.
16 It is worth noting that among the most suspicious demographic distortions of the Adjusted National Poll in E2004 was the Party ID cross-tab which indicated an electorate evenly divided between self-identified Democrats and Republicans, at 37% apiece. Not only was this supposed parity unprecedented, but it flew in the face of near-universal observational indications of a major Democratic turnout victory in 2004: not only in Ohio but nationwide, long lines and hours-long waits were recorded at inner-city and traditionally Democratic precincts, while literally no such lines were observed and no such complaints recorded in traditionally Republican voting areas (see EIRS data at https://voteprotect.org/index.php?display=EIRMapNation&tab=ED04).
_____________________________________________________________________________________________
The Adjusted National Poll: Making The Vote-Count Match
In the wake of our primary analysis of the validity of the Weighted National Poll, consideration of the Adjusted National Poll is something of an afterthought, though it does serve to further reinforce our conclusions.
As we described earlier, in the “adjusted” or “corrected” poll the pollster overrides all previous weighting to make the “Who did you vote for?” result in a given race (or set of races) match the vote count for that race, however it distorts the demographics of the sample. In the Adjusted National Poll, which appeared the day after the election and remains posted (with a few further updates not affecting this analysis) on the CNN.com website, Edison/Mitofsky was faced with the task of matching the tabulated aggregate results for the set of House races nationwide. This translated to reducing the Democratic margin from 11.5% to 7.6% by giving less weight to the respondents who said they had voted for a Democratic candidate and more weight to the respondents who said they had voted Republican. Of course this process, referred to as “forcing,” also affects the response to every question on the questionnaire, including the demographic and political preference questions we have been considering.
The most significant effect was upon “Vote for President in 2004.” In order to match the results of the official tally, the Adjusted National Poll was forced to depict an electorate that voted for Bush over Kerry by a 6% margin in 2004, more than twice the “actual” margin of 2.8%, taken charitably at face value for the purposes of this analysis.

As might be expected, other yardsticks were also affected: Bush approval increases to 43%; Congressional approval to 37%; and Party ID shifts to an implausible 38% Democratic, 36% Republican.
There were, as we identified earlier, indications that the Weighted National Poll itself may have undersampled voters who cast their votes for the Democratic House candidates.
See Appendix 1 for detailed tabular presentation of the above data.
_______________________________________________________________________________________________
17 To the extent that weighting is based on prior turnout patterns, a significant shift in the turnout dynamic, as was apparent in E2006, would be one cause for this undersampling. A second and more disturbing cause: “actual” results from recent elections, which themselves have been vulnerable to and distorted by electronic mistabulation, fed into the weighting algorithms.
18 The 11.5% Democratic margin in the Weighted National Poll was strictly congruent with the 11.5% average margin of the seven major national public opinion polls conducted immediately prior to the election. Indeed, this 11.5% pre-election margin was drawn down substantially by the appearance of three election-week “outlier” polls, which strangely came in at 7%, 6%, and 4% respectively. To put this in perspective, excluding these three polls, 30 of the 31 other major national polls published from the beginning of October up to the election showed the Democratic margin to be in double-digits, and the single exception came in at 9% (http://www.realclearpolitics.com/epolls/2006/house/us/generic_congressional_ballot-22.html). It is also worth noting that most pre-election polls shift, in the month before the election, to a "likely-voter cutoff model" (LCVM) that excludes entirely any voters not highly likely (on the basis of a battery of screening questions) to cast ballots; that is, it excludes entirely voters with a 25% or even 50% likelihood of voting. Since these are disproportionately transients and first-time voters, the less educated and affluent, it is also a correspondingly Democratic constituency that is disproportionately excluded. Ideally these voters should be down-weighted to their estimated probability of voting, but that probability is not 0%. By excluding them entirely, these pre-election polls build in a pro-Republican bias of about 2-5%, which anomalously in 2006 appears to have been offset by the significantly greater enthusiasm for voting on the part of the Democrats, reflected in an elevated LCVM failure rate among Republicans responding negatively or ambivalently to the battery question about their intention to vote in E2006. Dr. Steven Freeman, visiting professor at the University of Pennsylvania’s Center for Organizational Dynamics, has examined this phenomenon in great detail. Of course, one of the reasons for the recent shift to the LVCM—a methodology that pollsters will generally admit is distorted but which they maintain nonetheless “gets it right”—is that pollsters are (i>not paid for methodological purity, they are paid to get it right. From the pollster’s standpoint, getting it right is the measure of their success whether the election is honest or the fix is in. The reality is that distorted vote counts and a distorted but “successful” pre-election polling methodology wind up corroborating and validating each other, with only the exit polls (drawn from actual voters) seeming out of step.
______________________________________________________________________________________________
Plausible Explanations?
Since, as we have seen, the Weighted National Poll’s inclusion of Democratic voters (or, better put, voters with characteristics making them likely to vote Democratic) either jibes with or falls somewhat short of established benchmarks for the electorate, there are only two possible explanations for the dramatic disparity between it and the official vote count: either Republicans unexpectedly turned out in droves and routed the Democrats in the E2006 turnout battle, or the official vote count is dramatically “off.”
To our knowledge no one has contended the former. With good reason: there are a plethora of measures, including individual precinct tallies and additional polling data that we will examine in the next section, that confirm the obvious—the Democrats were the runaway winners of the 2006 Get-Out-The-Vote battle. Indeed it is generally acknowledged that Republican voters stayed home in droves, dismayed and turned-off by the late-breaking run of scandals, bad news, and missteps.
Hence it must be the reported nationwide vote tally which is inaccurate. Although this is, to put it mildly, an unwelcome finding, it is unfortunately consonant with the many specific incidents of vote-switching and mistabulation reported in 2006, with an apparent competitive-contest targeting pattern,
____________________________________________________________________________________________
19 Indeed, once on-going analysis fully quantifies the extent of the Democrats’ turnout victory, it will be time to recalculate upward the magnitude of the vote miscount in 2006.
20 Our paper on competitive contest targeting is scheduled for publication in August 2007.
____________________________________________________________________________________________
So Why Did The Republicans Lose?
It will no doubt be objected that if such substantial manipulation of the vote counts is possible, why would it stop short of bringing about a general electoral victory? While we would naturally like to credit the heightened scrutiny engendered by the untiring efforts of election integrity groups, an awakening media, and a more informed and vigilant public; an alternative, more chilling, explanation has emerged--simply that the mechanics of manipulation (software modules, primarily; see Appendix 3) had to be deployed before late-breaking pre-election developments
To quantify the extraordinary effect of the various "October surprises," we reference the Cook Political Report National Tracking Poll's Generic Congressional Ballot, ordinarily a rather stable measure:

Thus the Democratic margin among most likely voters increased from 9% (50% - 41%) to 26% (61% - 35%) during the month of October, a 17% jump occurring after the vote-shifting mechanisms were, or could be, deployed.
It should be noted that among the various tracking polls, there were some that did not pick up the dramatic trend reflected in the Cook poll. Indeed, Cook’s own parallel tracking poll of all registered voters (not screened for likelihood of turnout) found only a modest gain of 2% in the Democratic margin over the same period. This is indicative of the phenomenon to which we have already made reference: what most boosted the Democrats during the month of October was an extraordinary gain in the relative motivation and likelihood of turning out among their voters. It supports our belief that it was primarily the exceptional turnout differential, understandably missed by exit polls calibrated to historical turnout patterns, that would have given the Democrats an even greater victory than the 11.5% reflected by the Weighted National Poll, in an honestly and accurately counted election.
_______________________________________________________________________________________________
21 The powerful impact of the succession of lurid scandals (Foley, Haggard, Sheerwood, et al) is clear from the Weighted National Poll responses in which voters were asked about the importance of "corruption/ethics:" 41% responded "extremely important" and another 33% "very important," the highest response of all the "importance" questions, outstripping even the importance of "terrorism." Iraq, another source of late-breaking negatives for the GOP, also scored high on the importance scale (36% "extremely," with this category breaking for the Democrats 61% - 38%).
22 http://www.cookpolitical.com/poll/ballot.php.
_______________________________________________________________________________________________
Implications
The 2006 Election gave the Democrats control of both houses of Congress, by margins of 31 seats (233 – 202) in the House and two seats (51 – 49) in the Senate. The Democrats won 20 House races and four Senate races by margins of 6% of the vote or less.
Absent a very Blue October, which came too late to be countered by deployment of additional vote-shifting mechanisms, we can conclude that, with the assistance of the vote-shifting mechanisms already deployed, the Republicans would almost certainly have maintained control of both houses of Congress.
This should be a rather sobering observation for Democrats looking ahead to their electoral future and assessing to what extent the system is broken as they contemplate the various legislative proposals for reform.
_______________________________________________________________________________________________
23 In the House: four races by 1%, four races by 2%, one race by 3%, 5 races by 4%, one race by 5%, five races by 6%, one race by 7%, five races by 8%, two races by 9%; in the Senate: two races by 1%, one race by 3%, one race by 6%, one race by 8%.
24 If we are correct in our assessment that the limitations on vote shifting were more temporal than spatial—that is, had more to do with timing of deployment than with the potential size of the shift—then only extraordinary and unanticipated eleventh-hour pre-election surges a la E2006 will suffice to overcome future foul play. However, whatever quantitative limits may apply to electronic vote shifting, it should obviously not be necessary to enjoy super-majority support in order to eke out electoral victories.
_______________________________________________________________________________________________
Conclusion
There is a remarkable degree of consensus among computer scientists,
We have arrived at a system of “faith-based” voting where we are simply asked to trust the integrity of the count produced by the secret-software machines that tally our votes, without effective check mechanisms. In the context of yet another election replete with reported problems with vote tallying,
False elections bequeath to all Americans—right, left, and center—nothing less sinister than an illusory identity and the living of a national lie. Our biennial elections, far more than the endless parade of opinion polls, define America—both in terms of who occupies its seats of power and as the single snapshot that becomes the enduring national self-portrait that all Americans carry in their mental wallets for at least the biennium and more often for an era. It is also, needless to say, the portrait we send abroad.
While the reported results of the 2006 election were certainly well-received by the Democratic party and were ballpark-consistent with public expectations of a Democratic victory, the unadjusted 2006 exit poll data indicates that what has been cast as a typical midterm setback for a struggling president in his second term was something rather more remarkable – a landslide repudiation of historic proportions.
We believe that the demographic validity of the Weighted National Poll in 2006 is the clearest possible warning that the ever-growing catalog of reported vulnerabilities in America’s electronic vote counting systems are not only possible to exploit, they are actually being exploited. To those who would rush to find “innocent” explanations on an ad hoc basis for the cascade of mathematical evidence that continues to emerge, we ask what purpose is served and what comfort is given by relying on a series of implausible alibis to dispel concerns and head off effective reform?
The vulnerability is manifest; he stakes are enormous; the incentive is obvious; the evidence is strong and persistent. Any system so clearly at risk of interference and gross manipulation can not and must not be trusted to tally the votes in any future elections.
_______________________________________________________________________________________________
25 For instance http://www.acm.org/usacm/weblog/index.php?cat=6.
26 See the credentials of the interdisciplinary Brennan Center Task Force membership at
http://brennancenter.org/dynamic/subpages/download_file_36343.pdf.
27 http://www.gao.gov/new.items/d05956.pdf.
28 See http://www.blackboxvoting.org/BBVtsxstudy.pdf, http://www.blackboxvoting.org/BBVtsxstudysupp.pdf, and http://www.blackboxvoting.org/BBVreport.pdf.
29 Credible reports of voting equipment malfunctions are all too common; one good starting point is
http://www.votersunite.org/info/messupsbyvendor.asp.
30 For example, http://brennancenter.org/programs/downloads/SecurityFull7-3Reduced.pdf.
31 Election 2006 incidents at http://www.votersunite.org/electionproblems.asp.
_______________________________________________________________________________________________

2. Exit Poll Screen Captures
Exit poll screen capture files will be posted at http://www.electiondefensealliance.org/ExitPollData after the release of this report.


Apprendix 2 - NEP Methodology 2004 and 2007
METHODS STATEMENT
NATIONAL ELECTION POOL EXIT POLLS
November 2, 2004
NATIONAL/REGIONAL EXIT POLL
Edison Media Research and Mitofsky International conducted exit polls in each state and nationally for the National Election Pool (ABC, AP, CBS, CNN, FOX, NEC). The polls should be referred to as a National Election Pool (or NEP) Exit Poll, conducted by Edison/Mitofsky. All questionnaires were prepared by NEP.
The National exit poll was conducted at a sample of 250 polling places among 11,719 Election Day voters representative of the United States.
In addition, 500 absentee and/or early voters in 13 states were interviewed in a pre-election telephone poll. Absentee or early voters were asked the same questions asked at the polling place on Election Day. The absentee results were combined in approximately the correct proportion with voters interviewed at the polling places. The states where absentee/early voters were interviewed for the National exit poll are: Arizona, California, Colorado, Florida, Iowa, Michigan, Nevada, New Mexico, North Carolina, Oregon, Tennessee, Texas and Washington state. Absentee voters in these states made up 13% of the total national vote in the 2000 presidential election. Another 3% of the 2000 total vote was cast absentee in other states in 2000 and where there is no absentee/early voter telephone poll.
The polling places were selected as a stratified probability sample of each state. A subsample of the state samples was selected at the proper proportions for the National exit poll. Within each polling place an interviewer approached every n
For the national tabulations used to analyze an election, respondents are weighted based upon two factors. They are: (1) the probability of selection of the precinct and the respondent within the precinct; (2) by the size and distribution of the best estimate of the vote within geographic subregions of the nation. The second step produces consistent estimates at the time of the tabulation whether from the tabulations or an estimating model used to make an estimate of the national popular vote. At other times the estimated national popular vote may differ somewhat from the national tabulations.
All samples are approximations. A measure of the approximation is called the sampling error. Sampling error is affected by the design of the sample, the characteristic being measured and the number of people who have the characteristic. If a characteristic is found in roughly the same proportions in all precincts the sampling error will be lower. If the characteristic is concentrated in a few precincts the sampling error will be larger. Gender would be a good example of a characteristic with a lower sampling error. Characteristics for minority racial groups will have larger sampling errors.
The table below lists typical sampling errors for given size subgroups for a 95% confidence interval. The values in the table should be added and subtracted from the characteristic's percentage in order to construct an interval. 95% of the intervals created this way will contain the value that would be obtained if all voters were interviewed using the same procedures. Other non-sampling factors, including nonresponse, are likely to increase the total error.

* chart bolding ours
From National Election Pool FAQs 2007
What is the Margin of Error for an exit poll?
Every number estimated from a sample may depart from the official vote count. The difference between a sample result and the number one would get if everyone who cast a vote was interviewed in exactly the same way is called the sampling error. That does not mean the sample result is wrong. Instead, it refers to the potential error due to sampling. The margin of error for a 95% confidence interval is about +/- 3% for a typical characteristic from the national exit poll and +/-4% for a typical state exit poll.* Characteristics that are more concentrated in a few polling places, such as race, have larger sampling errors. Other nonsampling factors may increase the total error.
* bolding ours
Appendix 3 – Mechanics of Vote Manipulation
Practical Constraints on any Nationwide Covert Vote Manipulation Capability
Some critics of the initial draft of this paper released in November 2006 questioned whether it was possible that a systematic tabulation bias could ever be deployed to electronic voting equipment on a nationwide scale without being detected. Others claimed that if that capability truly existed, it should guarantee that one party would remain in permanent control.
The technical and logistical challenges inherent in any attempt to secretly corrupt vote tabulation on a nationwide basis are of course hardly trivial, but expert consensus is that there are multiple credible methods. We believe that the potential methods that could feasibly be used to implement widespread electronic vote manipulation on a national scale with a high probability of remaining undetected are such that a significant lead time would be required prior to the election. There is therefore a risk that any unexpected late-breaking pre-election developments could overcome a pre-programmed bias.
Voting systems risk assessment
Modern American electronic voting systems are geographically dispersed, distributed computer systems which are used intensively but infrequently. The end-to-end voting systems contain thousands of central tabulators and hundreds of thousands of in-precinct voting devices, all of which are purchased, maintained, upgraded, programmed, tested and used in actual elections in over 170,000 precincts across the United States on irregular schedules.
Through hands-on access, individual voting machines can be compromised one at a time through a variety of well-documented exploits.
Undetected widespread vote count corruption would certainly be not only the greatest computer security exploit of all time, it would be the greatest—and, in terms of the ultimate stakes, most lucrative—undetected crime in history. One must presume that any individuals capable of successfully pulling off such an exploit are clever, ruthless, and utterly determined to cover their tracks. We would not expect them to display naiveté nor simplicity, but rather to act at every step to preserve total secrecy of their presence and activities.
Voting system attacks that minimize the number of people involved
The June 2006 Brennan Center report described in great detail precisely how software patches, ballot definition files, and memory cards could be used to enable just one individual to alter the outcome of an election conducted either on touchscreen DREs
As the Brennan Center report notes:
. . . [I]n a close statewide election . . . “retail” attacks, or attacks on individual polling places, would not likely affect enough votes to change the outcome. By contrast, the less difficult attacks are centralized attacks: these would occur against the entire voting system and allow an attacker to target many votes with few informed participants.
Least difficult among these less difficult attacks would be attacks that use Software Attack Programs. The reason is relatively straightforward: a software attack allows a single knowledgeable person (or, in some cases, small group of people) to reach hundreds or thousands of machines. For instance, software updates and patches are often sent to jurisdictions throughout a state. Similarly, replaceable media such as memory cards and ballot definition files are generally programmed at the county level (or at the vendor) and sent to every polling place in the county.
These attacks have other benefits: unlike retail denial-of-service attacks, or manual shut off of machine functions, they could provide an attacker's favored candidate with a relatively certain benefit (i.e., addition of x number of votes per machine attacked). And if installed in a clever way, these attacks have a good chance of eluding the standard inspection and testing regimens currently in place.
Long-term evasion of detection
Since it is clear that the motivation exists to take covert control of electronic voting in the United States and that there are credible mechanisms for a small number of malicious insiders at voting equipment vendors to do so, long-term success boils down to evading detection—and so maintaining this power over time. One critical element of maintaining long-term secrecy would be the tradeoff of carefully calibrating the degree of vote manipulation to avoid attracting suspicion, while also ensuring the desired political outcome.
An individual in the position to introduce a covert vote manipulation software component into the operating system, firmware, device driver, or voting application itself would want to minimize risk of future detection and maximize the ease of changing the outcome of future contests. Ideally covert vote manipulation logic itself should be built into the machine as close to the factory as possible, rather than requiring redistribution of malicious program logic every election cycle; any change to the logic of a complex system could introduce new errors into the behavior of “benign” tabulation logic. And since political circumstances change, not all contests, elections and machines would be subject to the same type and degree of vote manipulation in every election, or the existence of the “Trojan Horse” itself would become all too evident.
Perhaps the easiest method to achieve both goals—long-term secrecy and long-term flexibility—is to introduce a general-purpose vote manipulation component which remains hidden within in the voting equipment for a long period of time, and which can be activated on demand by receipt of an external trigger. The trigger would not only activate the malicious software, but would also contain a parameter defining the size of the manipulation to implement. This is far from science fiction; parameterization is a basic computer software technique in use since the dawn of computing, and parameterization of voting equipment exploits is a powerful attack that is certainly technically feasible.
Although of course we cannot know for certain in the absence of a proper investigation whether this was actually done in 2006, there is strong support for a hypothesis that the logistics of introducing malicious programming on a targeted nationwide basis is both technically feasible and would likely require a substantial lead time, necessitating deployment prior to this past October’s “perfect storm.”
_______________________________________________________________________________________________
32 See footnotes 16-22 above.
33 Brennan Center June 2006 Report: "The Machinery of Democracy: Protecting Elections in an Electronic World," pp. 34 - 40.
34 ibid, p. 78.
35 ibid, p.48
36 ibid, p. 38.
| Attachment | Size |
|---|---|
| HOUSE_EP_1PM.pdf | 243.29 KB |
| HOUSE_EP_7PM.pdf | 243.33 KB |
| LandslideDenied_v.9_071507.pdf | 270.42 KB |




